
Spark SQL中对Json支持的详细介绍
在该文中,我将介绍一下Spark SQL对Json的支持,这个特性是Databricks的开发者们的努力结果,它的目的就是在Spark中使得查询和创建 *** ON数据变得非常地简单。随着WEB和手机应用的流行, *** ON格式的数据已经是WEB Service API之间通信以及数据的长期保存的事实上的标准格式了。但是使用现有的工具,用户常常需要开发出复杂的程序来读写分析系统中的 *** ON数据集。而Spark SQL中对 *** ON数据的支持极大地简化了使用 *** ON数据的终端的相关工作,Spark SQL对 *** ON数据的支持是从1.1版本开始发布,并且在Spark 1.2版本中进行了加强。
现有Json工具实践
在实践中,用户往往在处理现代分析系统中 *** ON格式的数据中遇到各种各样的困难。假如用户需要将数据集写成 *** ON格式的话,他们需要编写复杂的逻辑程序来转换他们的数据集到 *** ON格式中。假如需要读取或者查询 *** ON数据集,他们通常需要预先定义好数据结构并用它来转换 *** ON数据。在这种情况下,用户必须等待这些数据处理完成之后,才能够使用他们生成的 *** ON数据。无论是在写或者是读,预先定义和维护这些模式往往使得Etl工作变得非常地繁重!并且可能消除掉 *** ON这种半结构化(semi-structured)的数据格式的好处。假如用户想消费新的数据,他们不得不在创建外部表的时候定义好相关的模式,并使用自定义的 *** ON serialization/deserialization依赖库,或者是在查询 *** ON数据的时候使用UDF函数。
作为一个例子,假如有下面的一些 *** ON数据模式
{"name":"Yin", "address":{"city":"Columbus","state":"Ohio"}}
{"name":"Michael", "address":{"city":null, "state":"California"}}
在类似于Hive的系统中,这些 *** ON对象往往作为一个值储存到单个的列中,假如需要访问这个数据,我们需要使用UDF来抽取出我们需要的数据。在下面的SQL查询例子中,外层的字段(name和address)被抽取出来,嵌套在内层的address字段也被进一步的抽取出来:
/**
* User: 过往记忆
* Date: 15-02-04
* Time: 上午07:30
* bolg: http://www.iteblog.com
* 本文地址:http://www.iteblog.com/archives/1260
* 过往记忆博客,专注于hadoop、hive、spark、shark、flume的技术博客,大量的干货
* 过往记忆博客微信公共帐号:iteblog_hadoop
*/
SELECT
v1.name, v2.city, v2.state
FROM people
LATERAL VIEW json_tuple(people.jsonObject, 'name', 'address') v1
as name, address
LATERAL VIEW json_tuple(v1.address, 'city', 'state') v2
as city, state;
Spark SQL中对 *** ON的支持
Spark SQL提供了内置的语法来查询这些 *** ON数据,并且在读写过程中自动地推断出 *** ON数据的模式。Spark SQL可以解析出 *** ON数据中嵌套的字段,并且允许用户直接访问这些字段,而不需要任何显示的转换操作。上面的查询语句假如使用Spark SQL的话,可以这样来写:
SELECT name, age, address.city, address.state FROM people
在Spark SQL中加载和保存 *** ON数据集
为了能够在Spark SQL中查询到 *** ON数据集,唯一需要注意的地方就是指定这些 *** ON数据存储的位置。这些数据集的模式是直接可以推断出来,并且内置就有相关的语法支持,不需要用户显示的定义。在编程中使用API中,我们可以使用SQLContext提供的jsonFile和jsonRDD *** 。使用这两个 *** ,我们可以利用提供的 *** ON数据集来创建SchemaRDD 对象。并且你可以将SchemaRDD 注册成表。下面是一个很好的例子:
/**
* User: 过往记忆
* Date: 15-02-04
* Time: 上午07:30
* bolg: http://www.iteblog.com
* 本文地址:http://www.iteblog.com/archives/1260
* 过往记忆博客,专注于hadoop、hive、spark、shark、flume的技术博客,大量的干货
* 过往记忆博客微信公共帐号:iteblog_hadoop
*/
// Create a SQLContext (sc is an existing SparkContext)
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// Suppose that you have a text file called people with the following content:
// {"name":"Yin", "address":{"city":"Columbus","state":"Ohio"}}
// {"name":"Michael", "address":{"city":null, "state":"California"}}
// Create a SchemaRDD for the *** ON dataset.
val people = sqlContext.jsonFile("[the path to file people]")
// Register the created SchemaRDD as a temporary table.
people.registerTempTable("people")
当然,我们也可以使用纯的SQL语句来创建 *** ON数据集。例如
CREATE TEMPORARY TABLE people USING org.apache.spark.sql.json OPTIONS (path '[the path to the *** ON dataset]')
在上面的例子中,因为我们没有显示地定义模式,Spark SQL能够自动地扫描这些 *** ON数据集,从而推断出相关的模式。假如一个字段是 *** ON对象或者数组,Spark SQL将使用STRUCT 类型或者ARRAY类型来代表这些字段。即使 *** ON数是半结构化的数据,并且不同的元素肯恩好拥有不同的模式,但是Spark SQL仍然可以解决这些问题。假如你想知道 *** ON数据集的模式,你可以通过使用返回来的SchemaRDD 对象中提供的printSchema()函数来打印出相应的模式,或者你也可以在SQL中使用DESCRIBE [table name] 。例如上面的people数据集的模式可以通过people.printSchema() 打印出:
root |-- address: struct (nullable = true) | |-- city: string (nullable = true) | |-- state: string (nullable = true) |-- name: string (nullable = true)
当然,用户在利用 jsonFile 或 jsonRDD创建表的时候也可以显示的指定一个模式到 *** ON数据集中。在这种情况下,Spark SQL将把这个模式和 *** ON数据集进行绑定,并且将不再会去推测它的模式。用户不需要了解 *** ON数据集中所有的字段。指定的模式可以是固定数据集的一个子集,也可以包含 *** ON数据集中不存在的字段。
当用户创建好代表 *** ON数据集的表时,用户可以很简单地利用SQL来对这个 *** ON数据集进行查询,就像你查询普通的表一样。在Spark SQL中所有的查询,查询的返回值是SchemaRDD对象。例如:
val nameAndAddress = sqlContext.sql("SELECT name, address.city, address.state FROM people")
nameAndAddress.collect.foreach(println)
查询的结果可以直接使用,或者是被其他的分析任务使用,比如机器学习。当然, *** ON数据集可以通过Spark SQL内置的内存列式存储格式进行存储,也可以存储成其他格式,比如Parquet或者 Avro。
将SchemaRDD对象保存成 *** ON文件
在Spark SQL中,SchemaRDDs可以通过to *** ON *** 保存成 *** ON格式的文件。因为SchemaRDD中已经包含了相应的模式,所以Spark SQL可以自动地将该数据集转换成 *** ON,而不需要用户显示地指定。当然,SchemaRDDs可以通过很多其他格式的数据源进行创建,比如Hive tables、 Parquet文件、 JDBC、Avro文件以及其他SchemaRDD的结果。这就意味着用户可以很方便地将数据写成 *** ON格式,而不需要考虑到源数据集的来源。
“Spark SQL中对Json支持的详细介绍” 的相关文章
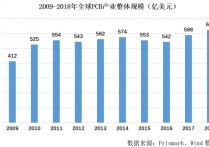
高强度竞争领域注定容不下安逸,等待敲锣的协和电子正走在掉队的路上?
扎根印制电路板技术研发二十年,专注于汽车电子、高频通讯等中高端领域的协和电子(605258)本周启动招股,下周四(11月19日)即将网上申购。 多年的沉淀,令其收获了一批优质客户。不过随着行业规模增长放缓、各类成本抬升以及行业龙头集中度提高,协和电子往日优势逐渐消退,利润水平也逐年降低,此...
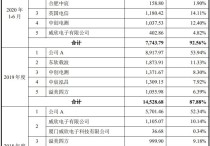
手握采购、研发、销售三条“命脉” 谁是操控创耀科技命运的神秘“公司A”
1947年,美国贝尔实验室的威廉.肖克利和他的两位助手布拉顿、巴丁,研制出了世界上第一只晶体管,为集成电路产业打开时代大门,也造就了现代信息社会的根基――“芯片”。 但是现代信息社会并不能避不开国与国之间的问题。 “芯片强则产业强,芯片兴则经济兴,没有高端芯片就没有真正的产业安全和国...
威腾电气IPO观察:自夸“头部企业”被打回原形 拿投资者4个亿只为“试试水”?
威腾电气,一家缺乏科创属性、爱夸夸其谈还带着问题供应商的公司,正在冲击科创板市场。 2021年1月14日,以输配电中母线产品研发、制造及销售为主业的威腾电气,正式通过上市委会议,距离科创板上市又近了一步。 但这对投资者而言,可能并不是一件好事。 由于身在传统电力行业,科研步伐又...

市占率不足0.1% 造血能力不足 罗普特科创上市谋续命?
钱流不进口袋的企业,真的算是赚钱企业吗? 盈利,是大部分投资者最关心的问题。但企业盈利的有效性,是有前提的,现金流就是这个前提。但这部分,往往会被许多投资者忽略,正如巴菲特的那句著名评论:“现金是氧气,99%的时间你不会注意它,直到它没有了”。 没有现金流入的盈利只是纸面数字,纸面数...
19%市占率换不来业绩体量的和林微纳 新业务0.24%市占率又该如何期待?
以19%市占率位居精微屏蔽罩市场头部玩家的和林微纳,即将亮相科创板。 2021年3月9日,主要产品为微机电(MEMS)精微电子零部件的和林微纳,开启了科创板招股。公司与楼氏电子、瑞声科技、裕元电子和银河机械,一同成为精微屏蔽罩市场的主要玩家,2019年五家企业合计占到全球市场总份额的80%...

新风光:核心材料严重依赖进口 毛利率下滑市场“风光”不再 |
作为“光伏、风电”等大热门行业上游关键零部件供应商的新风光,即将登陆科创资本市场。 2021年3月24日,以大功率电力电子节能控制技术为核心技术平台,构筑电气控制装备产品体系的新风光,在科创板开启招股环节。 招股资料显示,新风光本次共计将募资5.9亿元,其中1.5亿元用于变频器和SV...
- 最新文章
- 热门阅读
-
- 站长需要掌握的知识与技能
114 浏览站长资讯
- 马斯克:特斯拉2024年AI投资百亿,FSD 安全水平将超过人类
104 浏览站长资讯
- H5项目调用微信授权并实现登录功能
97 浏览未命名
- 西部数据WD 25年第三季度财报:营收为 22.9 亿美元,环比下降 5%
90 浏览站长资讯
- 新站怎样做好网络营销步实用方案解决推广难题实现长期排名
89 浏览SEO推广
- 站长需要掌握的知识与技能
-
最新文章
随机文章
热门文章
-
 重整计划刚获批:*ST景峰子公司陷3000万诉讼一审败诉,已上诉2026-02-04 阅读(0)
重整计划刚获批:*ST景峰子公司陷3000万诉讼一审败诉,已上诉2026-02-04 阅读(0) -
 【3日资金路线图】电力设备板块净流入逾251亿元居首 龙虎榜机构抢筹多股2026-02-03 阅读(1)
【3日资金路线图】电力设备板块净流入逾251亿元居首 龙虎榜机构抢筹多股2026-02-03 阅读(1) -
 Mhmarkets迈汇:去杠杆潮引发金银技术性调整2026-02-03 阅读(1)
Mhmarkets迈汇:去杠杆潮引发金银技术性调整2026-02-03 阅读(1) -
获资金追捧") 天孚通信7日飙涨超42%创新高!光模块“估值盛宴”到哪了?创业板人工智能ETF(159363)获资金追捧2026-02-03 阅读(1)
天孚通信7日飙涨超42%创新高!光模块“估值盛宴”到哪了?创业板人工智能ETF(159363)获资金追捧2026-02-03 阅读(1) -
 特朗普阵营中期选举前募款4.29亿美元,加密和AI巨头慷慨解囊!2026-02-03 阅读(1)
特朗普阵营中期选举前募款4.29亿美元,加密和AI巨头慷慨解囊!2026-02-03 阅读(1) -
 德弘入主后再现人事动荡?大润发否认高鑫零售CEO李卫平被查2026-02-03 阅读(1)
德弘入主后再现人事动荡?大润发否认高鑫零售CEO李卫平被查2026-02-03 阅读(1) -
 云内动力索赔征集中,投资者还可参与2026-02-03 阅读(1)
云内动力索赔征集中,投资者还可参与2026-02-03 阅读(1) -
 腾讯控股一度大跌6%,只因一则传言?2026-02-03 阅读(1)
腾讯控股一度大跌6%,只因一则传言?2026-02-03 阅读(1)
-
 如何删除自带的不常用应用为windows 7减负2001-12-01 阅读(45)
如何删除自带的不常用应用为windows 7减负2001-12-01 阅读(45) -
 windows 7系统开机后出现黑屏提示Windows无法启动2002-01-01 阅读(38)
windows 7系统开机后出现黑屏提示Windows无法启动2002-01-01 阅读(38) -
 ubuntu14.04打开个几个应用窗口最小化后怎么切换呢?2002-01-01 阅读(37)
ubuntu14.04打开个几个应用窗口最小化后怎么切换呢?2002-01-01 阅读(37) -
 windows 7系统怎么取消禁ping命令?2002-01-01 阅读(39)
windows 7系统怎么取消禁ping命令?2002-01-01 阅读(39) -
 windows 7如何创建拨号连接2002-01-01 阅读(40)
windows 7如何创建拨号连接2002-01-01 阅读(40) -
 windows7系统下让所有文件夹都使用同一种视图的方法2002-01-01 阅读(39)
windows7系统下让所有文件夹都使用同一种视图的方法2002-01-01 阅读(39) -
 windows 7/8/xp系统关闭自动播放功能禁止音频媒体自动播放2002-02-01 阅读(38)
windows 7/8/xp系统关闭自动播放功能禁止音频媒体自动播放2002-02-01 阅读(38) -
 windows 7启动后检测到硬盘出错提示请立即备份文件2002-02-01 阅读(30)
windows 7启动后检测到硬盘出错提示请立即备份文件2002-02-01 阅读(30)
-
 Windows7安装Solr+Tomcat的方法2010-05-01 阅读(215)
Windows7安装Solr+Tomcat的方法2010-05-01 阅读(215) -
 windows 7下先装SQL2005后装SQL2000 正确连接方法2010-10-01 阅读(143)
windows 7下先装SQL2005后装SQL2000 正确连接方法2010-10-01 阅读(143) -
 站长需要掌握的知识与技能2025-10-13 阅读(114)
站长需要掌握的知识与技能2025-10-13 阅读(114) -
 马斯克:特斯拉2024年AI投资百亿,FSD 安全水平将超过人类2025-03-21 阅读(104)
马斯克:特斯拉2024年AI投资百亿,FSD 安全水平将超过人类2025-03-21 阅读(104) -
 H5项目调用微信授权并实现登录功能2025-10-13 阅读(97)
H5项目调用微信授权并实现登录功能2025-10-13 阅读(97) -
 OpenStack 入门教程2015-05-14 阅读(94)
OpenStack 入门教程2015-05-14 阅读(94) -
 华为称已准备好取代谷歌应用:有10亿美元全球基金2019-12-25 阅读(93)
华为称已准备好取代谷歌应用:有10亿美元全球基金2019-12-25 阅读(93) -
 西部数据WD 25年第三季度财报:营收为 22.9 亿美元,环比下降 5%2025-05-02 阅读(90)
西部数据WD 25年第三季度财报:营收为 22.9 亿美元,环比下降 5%2025-05-02 阅读(90)
- 随机文章



v1.4.0 发布,知识付费解决方案")

- 热评文章
- 最近评论
-
